■Windows版Rubyの細道・けもの道
■ナビゲータ
Perlではどう処理する?
同じことをPerlではこうしています。2.基本編
2-3.マッチング(照合)処理
2-3-3.マージ処理
2つのCSVファイルを読み込んで、両方のファイルを1つにまとめるマージ処理を行うスクリプトです。
「1対1マッチング(照合)」を変形した処理であり、「マスタファイル」と「トランザクションファイル」の両方から統合した1つのファイルを作成する処理です。
注意すべき点は、出力ファイルにあわせてファイルハンドルを設定する点です。この例では、出力ファイルは1つのため、対応するファイルハンドルも1つになっています。仮に「マッチング(照合)したファイル」と「トランザクションファイル」を1つのファイルに出力し、「マスタオンリーファイル」と区別する場合は、ファイルハンドルを2つ設定することになります。マッチング(照合)用のスクリプトをそのまま持ってきて、ファイル名だけを変更すると誤った出力結果になるので注意する必要があります。
下記に示したのは、スクリプトの構造を示したPAD図です。この図と実際のスクリプトを比較しながら、内容を理解してください。なお、入力データはキー順に並べ替えてあることが前提となっています。Perlを利用して並べ替えを行う場合については、[2-4.ソート処理]を参照してください。
統合された1つのファイルに対して、「マスタファイル」や「トランザクションファイル」からどのようにデータをセットするかは、それぞれのケースによって異なるので、各自工夫してください。
「1対1マッチング(照合)」の変形だからといって、複数の異なる出力ファイルのファイルハンドルに対して、同一のデータを指定しないでください。処理の結果が保証されなくなりますので、十分注意してください。
【マージ処理のPAD図】
下記のPAD図は「ez-Chart ver1.0」 2003.2-3 cジュン All right received.を使用して作成されたものです。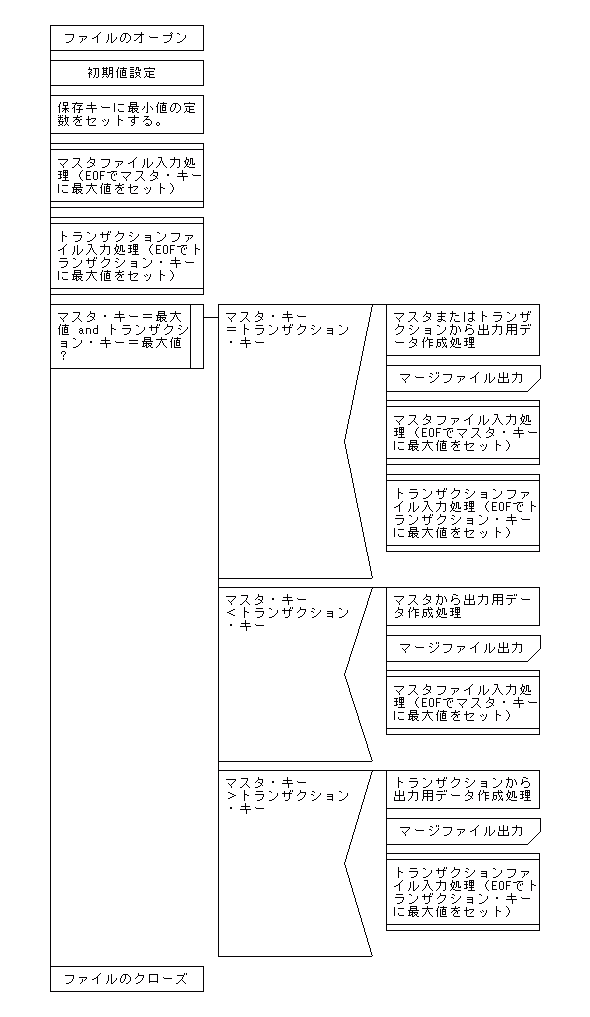
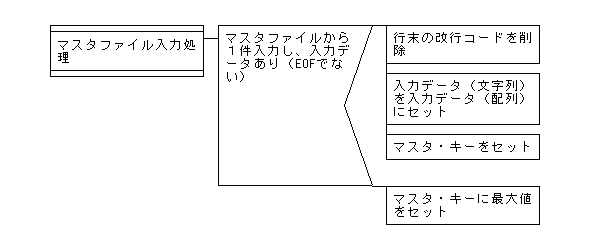
【マージ処理でのマスタファイル入力処理のPAD図】
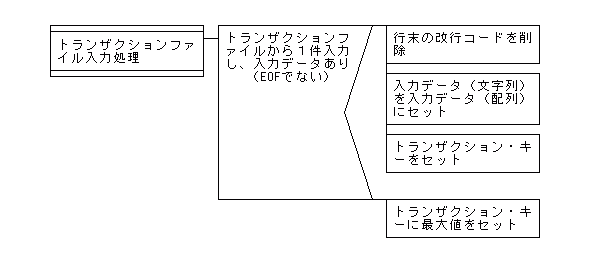
【マージ処理でのトランザクションファイル入力処理のPAD図】
【スクリプト】
# merge.rb
# 内容 : マージプログラム(2ファイルの1対1マッチングをした後、1ファイルに統合する)
# 前提 : マスターファイルとトランザクションファイルの両方を
# マージするキーごとに昇順に並べ替えておくこと
# Copyright (c) 2002-2015 Mitsuo Minagawa, All rights reserved.
# (minagawa@fb3.so-net.ne.jp)
# 使用方法 : c:\>ruby merge.rb
#
# ファイルのオープン
in1_file = open("master.txt","r") #マスターファイル
in2_file = open("transaction.txt","r") #トランザクションファイル
out1_file = open("merge.txt","w") #マージファイル
# 初期値設定
in1_eof = ["ffffffff"].pack("h8") #マスターファイルの終了判定
in2_eof = ["ffffffff"].pack("h8") #トランザクションファイルの終了判定
in1 = nil #マスターデータ
in1_key = nil #マスターキー
in2 = nil #トランザクションデータ
in2_key = nil #トランザクションキー
# マスタファイル入力
class S_in1
def dataset(in1_file,in1_eof)
if (line1 = in1_file.gets)
line1.chomp!
#タブ区切りのとき
# in1 = line1.split("\t",-1)
#カンマ区切りのとき
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
#キー項目が単独のとき
in1_key = in1[0]
#キー項目が複数のとき
#1番目と2番目と3番目の項目がキーとなる場合
# in1_key = in1[0]+in1[1]+in1[2]
#入力ファイルが終了のとき
else
in1 = nil
#マスターファイルの終了判定(in1_eof)をマスターキーにセット
in1_key = in1_eof
end
return in1,in1_key
end
end
# トランザクションファイル入力
class S_in2
def dataset(in2_file,in2_eof)
if (line2 = in2_file.gets)
line2.chomp!
#タブ区切りのとき
# in2 = line2.split("\t",-1)
#カンマ区切りのとき
in2 = (line2 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
#キー項目が単独のとき
in2_key = in2[0]
#キー項目が複数のとき
#1番目と2番目と3番目の項目がキーとなる場合
# in2_key = in2[0]+in2[1]+in2[2]
#入力ファイルが終了のとき
else
in2 = nil
#トランザクションファイルの終了判定(in2_eof)をトランザクションキーにセット
in2_key = in2_eof
end
return in2,in2_key
end
end
# マッチングファイルの出力
def s_match(in1,in2,out1_file)
out1 = in1.join("\t")
out1_file.print out1,"\n"
end
# マスターオンリーファイルの出力
def s_master_only(in1,out1_file)
out1 = in1.join("\t")
out1_file.print out1,"\n"
end
# トランザクションオンリーファイルの出力
def s_trans_only(in2,out1_file)
out1 = in2.join("\t")
out1_file.print out1,"\n"
end
# 1件目のデータ入力と配列へのデータセット等
s_in1 = S_in1.new
(in1,in1_key) = s_in1.dataset(in1_file,in1_eof)
s_in2 = S_in2.new
(in2,in2_key) = s_in2.dataset(in2_file,in2_eof)
# 主処理
until ((in1_key == in1_eof) &&
(in2_key == in2_eof))
# マッチングの時(両方のファイルにデータがある)
if (in1_key == in2_key)
s_match(in1,in2,out1_file)
(in1,in1_key) = s_in1.dataset(in1_file,in1_eof)
(in2,in2_key) = s_in2.dataset(in2_file,in2_eof)
# マスタオンリーの時(マスタファイルだけにデータがある)
elsif (in1_key < in2_key)
s_master_only(in1,out1_file)
(in1,in1_key) = s_in1.dataset(in1_file,in1_eof)
# トランザクションオンリーの時(トランザクションファイルだけにデータがある)
elsif (in1_key > in2_key)
s_trans_only(in2,out1_file)
(in2,in2_key) = s_in2.dataset(in2_file,in2_eof)
end
end
# ファイルのクローズ
in1_file.close
in2_file.close
out1_file.close
【スクリプトとデータのサンプル】
【スクリプトの解説】
マージ処理
# マッチングの時(両方のファイルにデータがある)
if (in1_key == in2_key)
s_match(in1,in2,out1_file)
(in1,in1_key) = s_in1.dataset(in1_file,in1_eof)
(in2,in2_key) = s_in2.dataset(in2_file,in2_eof)
# マスタオンリーの時(マスタファイルだけにデータがある)
elsif (in1_key < in2_key)
s_master_only(in1,out1_file)
(in1,in1_key) = s_in1.dataset(in1_file,in1_eof)
# トランザクションオンリーの時(トランザクションファイルだけにデータがある)
elsif (in1_key > in2_key)
s_trans_only(in2,out1_file)
(in2,in2_key) = s_in2.dataset(in2_file,in2_eof)
end
マージ処理はマッチング(照合)処理とほぼ同じような処理になりますが、出力先が1つになっている点が異なります。マッチング(照合)処理のように出力用のファイルハンドルを3つ用意して、それぞれに同じ出力ファイルを割り当てるようなことはしないでください。
その他注意すべきこと
その他、注意すべき点は入力データがタブ区切りなどの場合とキーが複数ある場合の処理です。
上記のスクリプトでは、入力ファイルがCSVファイルであれば、どのようなものでも対応できるようになっています。具体的には以下の箇所になります。
CSV形式の入力データを配列に変換する
#カンマ区切りのとき
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
上記のスクリプトはCSV2形式以外の引用符(")を使用する場合を含め、あらゆるCSVファイルに対応できるようになっています(CSV2形式などについては、[3-1-1.固定長データとCSVデータ]を参照してください)が、このCSVファイルに分解するロジックは、大崎 博基(OHZAKI Hiroki)さんの「Perlメモ」に記載されていたものを参考にしています。また、CSV2形式のCSVファイルであれば、上記のスクリプトは以下のように簡略化できます。
1.入力データがCSV2形式の場合、
in1 = line1.split(",",-1)
とします。
2.入力データがタブ区切りの場合、
in1 = line1.split("\t",-1)
とします。
3.キーが複数の項目から成り立っている場合は、
「$in1_key = $in1[0]」の部分を
in1_key = in1[0]+in1[1]+in1[2]
のように変更します(文字列の連結は「+」を使います)。
【入力データ:マスタファイル(master.txt)】
01,11111
02,22222
03,33333
05,44444
07,77777
08,88888
09,99999
【入力データ:トランザクションファイル(transaction.txt)】
01,100
02,200
04,400
06,600
07,700
08,800
09,900
10,1000
【出力データ(merge.txt)】
01,11111
02,22222
03,33333
04,400
05,44444
06,600
07,77777
08,88888
09,99999
10,1000
Copyright (c) 2004-2015 Mitsuo Minagawa, All rights reserved.