■Windows版Rubyの細道・けもの道
■ナビゲータ
- [Windows版Rubyの細道・けもの道]
- [1.準備編]
- [2.基本編]
- [2-1.基本処理]
- [2-2.キーブレイク処理]
- [2-2-1.各キーの1件目を出力(until型)]
- [2-2-2.各キーの最終レコードを出力(until型)]
- [2-2-3.同一キーでの合計処理(until型)]
- [2-2-4.同一キーでの件数カウント(until型)]
- [2-2-5.各キーの1件目を出力(while型)]
- [2-2-6.各キーの最終レコードを出力(while型)]
- [2-2-7.同一キーでの合計処理(while型)]
- [2-2-8.同一キーでの件数カウント(while型)]
- [2-2-9.ハッシュを使った同一キーの合計処理]
- [2-3.マッチング(照合)処理]
- [2-4.ソート(並べ替え)処理]
- [2-5.パターンマッチ処理]
- [3.応用編]
- [スクリプトと入力データのサンプル]
Perlではどう処理する?
同じことをPerlではこうしています。2.基本編
2-2.キーブレイク処理
2-2-8.同一キーでの件数カウント処理---while型の場合
CSVファイルを読み込んで、同一キーのレコードの件数をwhile命令を使って合計する処理です。[2-2-4.同一キーでの件数カウント(until型)]がuntil命令で行うのに対し、こちらはwhile命令を使います。
[2-2-4.同一キーでの件数カウント(until型)]の各キーごとの合計値を出力するスクリプトとほぼ同じような構造になっています。ただし、出力する内容が、保存したデータそのものではなく、入力件数であるため、キーが同じ間はデータを集計し、キーが変わったら入力件数をゼロにするタイミングを考えて作成する必要があります。このスクリプトでも、ファイルをクローズする前に入力データがゼロ件の場合かどうかを判断し、1件以上のデータがある場合は、入力件数が保存されたまま、出力されない状態で残っていることになるので、そのデータを出力する必要が生じます。
ポイントは、保存キーと入力キーが等しい場合は、合計件数に1件加算し、保存キーと入力キーが異なる場合で、保存キーが未定義値でない場合(=入力データが2件目以降の場合)、保存キーと合計件数を出力していることです。
下記に示したのは、スクリプトの構造を示したPAD図です。この図と実際のスクリプトを比較しながら、内容を理解してください。なお、入力データはキー順に並べ替えてあることが前提となっています。Rubyを利用して並べ替えを行う場合については、[2-4.ソート(並べ替え)処理]を参照してください。
【同一キーの件数をカウントする場合のwhileを利用したキーブレイク処理のPAD図】
下記のPAD図は「ez-Chart ver1.0」 2003.2-3 cジュン All right received.を使用して作成されたものです。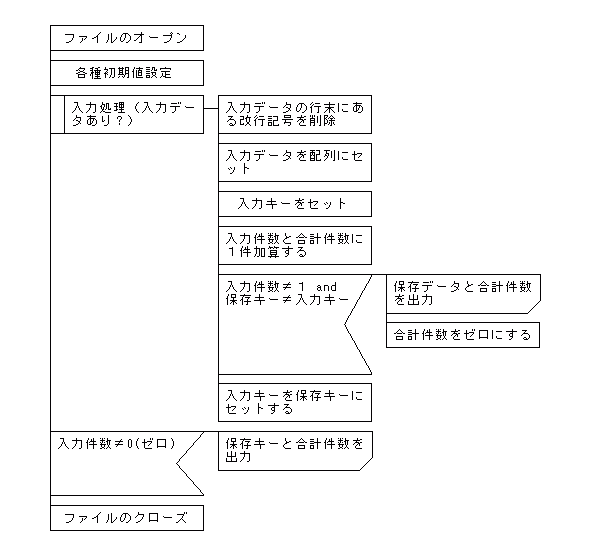
【スクリプト】
# countup2.rb
# 内容 : 同一キーの件数をカウントする(while型)
# 前提 : カウントするキーごとに昇順に並べ替えておくこと
# Copyright (c) 2002-2015 Mitsuo Minagawa, All rights reserved.
# (minagawa@fb3.so-net.ne.jp)
# 使用方法 : c:\>ruby countup2.rb
#
# 入力ファイル
in1_file = open("input.txt","r")
# 出力ファイル
out1_file = open("output.txt","w")
# 初期値設定
in1_key = nil #入力キー
sv_key = nil #保存キー
in1_ctr = 0 #入力件数
w_total = 0 #合計件数
# キーブレイク時の処理
def s_break(out1_file,sv_key,w_total)
out1 = [sv_key,w_total].join("\t")
out1_file.print out1,"\n"
end
# 主処理
while (line1 = in1_file.gets)
line1.chomp!
# タブ区切りのとき
# in1 = line1.split("\t",-1)
# カンマ区切りのとき
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
# キー項目が単独のとき
in1_key = in1[0]
# キー項目が複数のとき
# 1番目と2番目と3番目の項目がキーとなる場合
# in1_key = in1[0] + in1[1] + in1[2]
in1_ctr += 1
# キーブレイク時
if ((sv_key != nil) &&
(sv_key != in1_key))
s_break(out1_file,sv_key,w_total)
# w_totalをゼロにしなければ、合計件数ではなく、累計件数になる。
w_total = 0
end
#入力したキーを保存
sv_key = in1_key
#件数を加算
w_total += 1
end
# 最終データの処理(入力データがある場合)
if (in1_ctr != 0)
s_break(out1_file,sv_key,w_total)
end
# ファイルのクローズ
in1_file.close
out1_file.close
【スクリプトとデータのサンプル】
【スクリプトの解説】
# キーブレイク時
if ((sv_key != nil) &&
(sv_key != in1_key))
s_break(out1_file,sv_key,w_total)
# w_totalをゼロにしなければ、合計件数ではなく、累計件数になる。
w_total = 0
end
#入力したキーを保存
sv_key = in1_key
#件数を加算
w_total += 1
end
キーブレイク処理は、whileループ内で入力データのセットが終了した後に置きます。untilループと異なり、whileループでは、ループの外で入力処理を行わないため、特別な処理をしなければ、1件目キーは必ず、保存キーと異なっていることになります。
したがって、何もしなければ、最初にループに入った直後にキーブレイク処理が発生することになります。このため、キーごとの最初のデータでキーブレイク処理を行う場合は、このままで問題ないのですが、キーごとの最後のデータでキーブレイク処理を行う場合は、1件目のデータのみを例外とするような条件を入れておく必要があります。
合計件数(w_total)をゼロクリアするのは、キーブレイク処理の直後に行います。ここでゼロクリアしなければ、累計件数になります。ゼロクリアをキーブレイク処理(s_break)の中で行っても、ローカル変数に設定することになりますので、意味がありません。キーブレイク処理(s_break)の外に出ると、設定前の値に戻ってしまいます。
キーブレイク時の処理
# キーブレイク時の処理
def s_break(out1_file,sv_key,w_total)
out1 = [sv_key,w_total].join("\t")
out1_file.print out1,"\n"
end
キーブレイク処理は、whileのループ内と最終データの処理を行うところの2箇所で発生するため、サブルーチンを作成して、1箇所で記述しておきます。こうすることで変更が発生した場合に修正が容易にできるようになるだけでなく、修正箇所が他人から見てもわかりやすくなるのです。
その他注意すべきこと
その他、注意すべき点は入力データがタブ区切りなどの場合とキーが複数ある場合の処理です。
上記のスクリプトでは、入力ファイルがCSV形式であれば、すべて対応できるようになっていますが、引用符(")をつけないCSV形式(いわゆるCSV2形式と呼ばれるものです。CSV2形式については、[3-1-1.固定長データとCSVデータ]を参照してください)であれば、
# カンマ区切りのとき
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
上記の箇所を
in1 = line1.split(",",-1)
と変更します。
また、入力ファイルがタブ区切りの場合は以下のようにします。
入力データがタブ区切りの場合、
in1 = line1.split("\t",-1)
とします。
キーが複数の項目から成り立っている場合は、
「$in1_key = $in1[0]」の部分を
in1_key = in1[0]+in1[1]+in1[2]
のように変更します(文字列の連結は「+」(プラス)を使います)。
【入力データ(input.txt)】
aaa,1 aaa,2 aaa,3 bbb,1 ccc,1 ccc,2 ddd,1 ddd,2 ddd,3 ddd,4 eee,1 fff,1 ggg,1 hhh,1 hhh,2 hhh,3
【出力データ(output.txt):合計件数の場合】
aaa,3 bbb,1 ccc,2 ddd,4 eee,1 fff,1 ggg,1 hhh,3
【出力データ(output.txt):累計件数の場合】
aaa,3 bbb,4 ccc,6 ddd,10 eee,11 fff,12 ggg,13 hhh,16
Copyright (c) 2004-2015 Mitsuo Minagawa, All rights reserved.