■Windows版Rubyの細道・けもの道
■ナビゲータ
- [Windows版Rubyの細道・けもの道]
- [1.準備編]
- [2.基本編]
- [2-1.基本処理]
- [2-2.キーブレイク処理]
- [2-2-1.各キーの1件目を出力(until型)]
- [2-2-2.各キーの最終レコードを出力(until型)]
- [2-2-3.同一キーでの合計処理(until型)]
- [2-2-4.同一キーでの件数カウント(until型)]
- [2-2-5.各キーの1件目を出力(while型)]
- [2-2-6.各キーの最終レコードを出力(while型)]
- [2-2-7.同一キーでの合計処理(while型)]
- [2-2-8.同一キーでの件数カウント(while型)]
- [2-2-9.ハッシュを使った同一キーの合計処理]
- [2-3.マッチング(照合)処理]
- [2-4.ソート(並べ替え)処理]
- [2-5.パターンマッチ処理]
- [3.応用編]
- [スクリプトと入力データのサンプル]
Perlではどう処理する?
同じことをPerlではこうしています。2.基本編
2-2.キーブレイク処理
2-2-2.各キーの最終レコードを出力する---until型の場合
CSVファイルを読み込んで、各キーごとの最終レコードをuntil命令を使って出力する処理です。
たとえば、各キーごとにデータが古い順に並んでいるような場合に、このスクリプトによって、各キーごとの最後のレコードを取り出すことによって、最新のデータだけを取り出すことができるようになります。
各キーの1件目のデータを出力する場合と異なるのは、保存するのはキーだけでなく、データも保存しておく必要があるという点と出力するのは保存したデータであるという点です。これは現在読み込んでいるデータではなく、保存したデータを出力するためです。
このため、untilループ処理ですべてのキーブレイク処理を完結することができせん。したがって、ファイルをクローズする前に入力データがゼロ件の場合かどうかを判断し、1件以上のデータがある場合は、何らかのデータが保存されたまま、出力されない状態で残っていると判断し、そのデータを出力することになります。
ポイントは、1件目のレコードを入力したときに入力キーを保存キー(sv_key)に保存しておき、繰り返し処理の中で1件目から「保存キー≠入力キー」の条件に合致しないように初期設定していることです。
下記に示したのは、スクリプトの構造を示したPAD図です。この図と実際のスクリプトを比較しながら、内容を理解してください。なお、入力データはキー順に並べ替えてあることが前提となっています。Rubyを利用して並べ替えを行う場合については、[2-4.ソート(並べ替え)処理]を参照してください。
【各キーの最後のデータを出力する場合のuntilを利用したキーブレイク処理のPAD図】
下記のPAD図は「ez-Chart ver1.0」 2003.2-3 cジュン All right received.を使用して作成されたものです。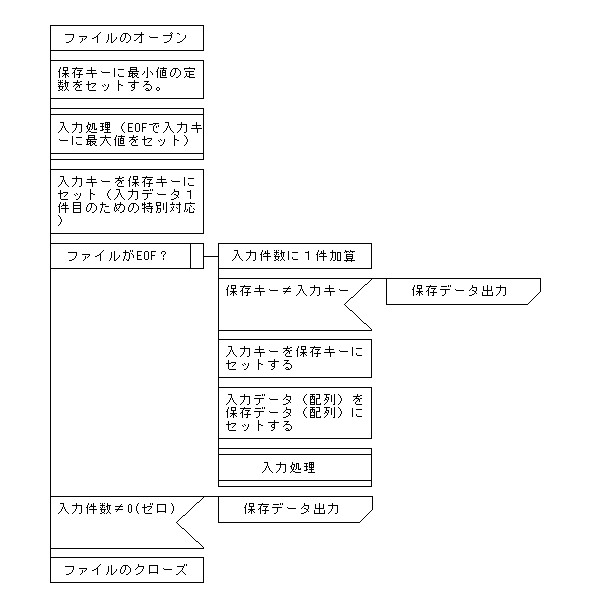
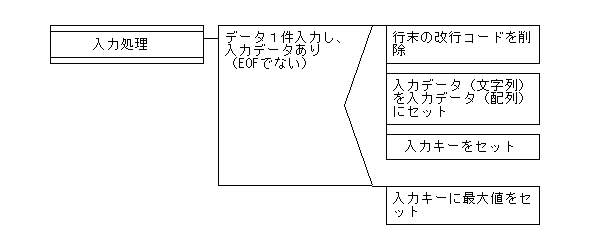
【untilを利用したときの入力処理のPAD図】
【スクリプト】
# keybreak2.rb
# 内容 : 同一キーの最後のデータを出力する(until型)
# 前提 : キーごとに昇順に並べ替えておくこと
# Copyright (c) 2002-2015 Mitsuo Minagawa, All rights reserved.
# (minagawa@fb3.so-net.ne.jp)
# 使用方法 : c:\>ruby keybreak2.rb
#
# 入力ファイル
in1_file = open("input.txt","r")
# 出力ファイル
out1_file = open("output.txt","w")
# 初期値設定
in1_eof = ["ffffffff"].pack("h8") #ファイルの終了判定
in1_key = nil #入力キー
in1 = nil #入力レコードを格納する配列
in1_ctr = 0 #入力件数
sv_key = nil #保存キー
save1 = nil #入力レコードを保存する配列
# データ入力処理
class S_in1
def dataset(in1_file,in1_ctr,in1_eof)
if (line1 = in1_file.gets)
line1.chomp!
#タブ区切りのとき
# in1 = line1.split("\t",-1)
#カンマ区切りのとき
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
# キー項目が単独のとき
in1_key = in1[0]
# キー項目が複数のとき
# 1番目と2番目と3番目の項目がキーとなる場合
# in1_key = in1[0] + in1[1] + in1[2]
in1_ctr += 1
#入力ファイルが終了のとき
else
in1 = nil
#入力ファイルの終了判定(in1_eof)を入力キーにセット
in1_key = in1_eof
end
return in1,in1_ctr,in1_key
end
end
# キーブレイク時の処理
def s_break(out1_file,save1)
out1 = save1.join("\t")
out1_file.print(out1,"\n")
# 以下のようにしても可
# out1_file.print save1.join("\t"),"\n"
end
# データ入力処理(1件目)およびキー項目セット
s_in1 = S_in1.new
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
sv_key = in1_key
# 主処理
#入力ファイルが終了になるまで
until (in1_key == in1_eof)
in1_ctr += 1
if (sv_key != in1_key)
s_break(out1_file,save1)
end
#入力レコードを格納した配列を保存
save1 = in1
#入力したキーを保存
sv_key = in1_key
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
end
# 最終データの処理(入力データがある場合)
if (in1_ctr != 0)
s_break(out1_file,save1)
end
# ファイルのクローズ
in1_file.close
out1_file.close
【スクリプトとデータのサンプル】
【スクリプトの解説】
それでは、スクリプトの解説を個別に行っていきましょう。
初期値設定
# 初期値設定
in1_eof = ["ffffffff"].pack("h8") #ファイルの終了判定
in1_key = nil #入力キー
in1 = nil #入力レコードを格納する配列
in1_ctr = 0 #入力件数
sv_key = nil #保存キー
save1 = nil #入力レコードを保存する配列
初期値設定では、文字列の最大値である「in1_eof」を設定しておきます。これは、入力ファイルが終了したことを示すEOFを検出したときに設定することに利用します。
1件目で必ずキーブレイク処理する場合は、入力キーと保存キーが必ず異なる値になるように「nil」を代入していましたが、同一キーの最後のデータでキーブレイクするためには、1件目でキーブレイクしないので、「nil」の代入は必要ありません。
「in1_ctr」は、入力件数をカウントする変数です。
「同一キーの最後のデータでキーブレイクする」ということは、入力データのキー項目がすべて同じだった場合、untilのループ内では何も出力されないことになります。
また、untilのループを抜けたところで必ず出力すると、入力データがない場合にも出力データが出力されることになります。
こうしたことを避けるため、変数「in1_ctr」で入力件数をカウントし、入力データがある場合にだけキーブレイク処理を行うようにしています。
また、こうした極端な例を持ち出さなくても、入力データの最後のデータだけがユニークなキー項目を持っている場合にも、上記のような対応をしないとそのデータは出力されないことになります。(わからない場合は試してみてください)
こうしたことを避けるためにも、untilのループを出た後で判定することが必要になってきます。このため、入力件数をカウントし、1件でも入力データがある場合にはキーブレイク処理を行うことにしているのです。
「in1」は入力レコードを各項目に分解した配列、「save1」保存したレコードを各項目に分解した配列でそれぞれ初期値として、「nil」を代入しておきます。この処理は省略してもかまいません。
それ以外に初期値として設定しておくような項目があれば、ここに設定しておきます。
入力処理
# データ入力処理(1件目)およびキー項目セット s_in1 = S_in1.new (in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof) sv_key = in1_key
まず、最初の文でユーザ定義クラス(S_in1)をもとにインスタンス(s_in1)を作成し、入力処理が利用できるようにしています。
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
次に、このインスタンス変数(s_in1)を利用し、ユーザ定義クラスの中で指定したメソッド定義(defで定義している部分)によって、戻り値(ここでは、メソッド定義の外で使用する項目として1行分の入力データの配列と入力件数、入力キー)をセットします。メソッド定義の外で使用する項目についてはすべて戻り値で指定します。
sv_key = in1_key
1件目のキーをすぐに保存キーに入れます。これにより、1件目ではキーブレイク処理は発生しないことになります。(ここが1件目のデータでキーブレイクする場合と異なる点です)
主処理
# 主処理
#入力ファイルが終了になるまで
until (in1_key == in1_eof)
in1_ctr += 1
if (sv_key != in1_key)
s_break(out1_file,save1)
end
#入力レコードを格納した配列を保存
save1 = in1
#入力したキーを保存
sv_key = in1_key
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
end
until の条件は、入力データが終了(EOF)したときの条件を入れます。
EOFを判定する項目とキー項目を別々にとってもかまわないのですが、終了条件が複雑になるだけでほとんどメリットはありません。むしろ、同じ項目にしたほうがわかりやすいことが多いのです。
このスクリプトでは、入力データをすべて出力していますが、何らかの項目に限定するのか、計算を行うのかによって、必要な処理に変更します。
各キーの1件目のデータを出力する場合と異なるのは、保存するのはキーだけでなく、データも保存しておく必要があるという点と出力するのは保存したデータであるという点です。これは現在読み込んでいるデータではなく、保存したデータを出力するためです。これを以下の2行で行っています。
#入力レコードを格納した配列を保存
save1 = in1
#入力したキーを保存
sv_key = in1_key
このため、untilループ処理ですべてのキーブレイク処理を完結することができせん。したがって、ファイルをクローズする前に入力データがゼロ件の場合かどうかを判断し、1件以上のデータがある場合は、何らかのデータが保存されたまま、出力されない状態で残っていると判断し、そのデータを出力することになります。具体的には、以下のようにします。
最終データの処理
# 最終データの処理(入力データがある場合)
if (in1_ctr != 0)
s_break(out1_file,save1)
end
ポイントは、1件目のレコードを入力したときに入力キーを保存キー(sv_key)に保存しておき、繰り返し処理の中で1件目から「保存キー≠入力キー」の条件に合致しないように初期設定していることです。
# データ入力処理(1件目)およびキー項目セット s_in1 = S_in1.new (in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof) sv_key = in1_key
その他注意すべきこと
その他、注意すべき点は入力データがタブ区切りなどの場合とキーが複数ある場合の処理です。
上記のスクリプトでは、入力ファイルがCSV形式であれば、すべて対応できるようになっていますが、引用符(")をつけないCSV形式(いわゆるCSV2形式と呼ばれるものです。CSV2形式については、[3-1-1.固定長データとCSVデータ]を参照してください)であれば、
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
上記の箇所を
in1 = line1.split(",",-1)
と変更します。
また、入力ファイルがタブ区切りの場合は以下のようにします。
入力データがタブ区切りの場合、
in1 = line1.split("\t",-1)
とします。
キーが複数の項目から成り立っている場合は、
「$in1_key = $in1[0]」の部分を
in1_key = in1[0]+in1[1]+in1[2]
のように変更します(文字列の連結は「+」(プラス)を使います)。
【入力データ(input.txt)】
aaa,1 aaa,2 aaa,3 bbb,1 ccc,1 ccc,2 ddd,1 ddd,2 ddd,3 ddd,4 eee,1 fff,1 ggg,1 hhh,1 hhh,2 hhh,3
【出力データ(output.txt)】
aaa,3 bbb,1 ccc,2 ddd,4 eee,1 fff,1 ggg,1 hhh,3
Copyright (c) 2004-2015 Mitsuo Minagawa, All rights reserved.