■Windows版Rubyの細道・けもの道
■ナビゲータ
- [Windows版Rubyの細道・けもの道]
- [1.準備編]
- [2.基本編]
- [2-1.基本処理]
- [2-2.キーブレイク処理]
- [2-2-1.各キーの1件目を出力(until型)]
- [2-2-2.各キーの最終レコードを出力(until型)]
- [2-2-3.同一キーでの合計処理(until型)]
- [2-2-4.同一キーでの件数カウント(until型)]
- [2-2-5.各キーの1件目を出力(while型)]
- [2-2-6.各キーの最終レコードを出力(while型)]
- [2-2-7.同一キーでの合計処理(while型)]
- [2-2-8.同一キーでの件数カウント(while型)]
- [2-2-9.ハッシュを使った同一キーの合計処理]
- [2-3.マッチング(照合)処理]
- [2-4.ソート(並べ替え)処理]
- [2-5.パターンマッチ処理]
- [3.応用編]
- [スクリプトと入力データのサンプル]
Perlではどう処理する?
同じことをPerlではこうしています。2.基本編
2-2.キーブレイク処理
2-2-1.各キーの1件目を出力する---until型の場合
CSVファイルを読み込んで、各キーごとの1件目に該当するレコードをuntil命令を使って出力する処理です。
until命令は、
until (繰り返しが終了する条件)
繰り返しで行う処理
end
と記述し、繰り返しが終了する条件を満たすまでは繰り返しの中の処理を実行します。until命令では、入力データが終了したかどうかの判断だけを行うため、繰り返し処理に入る前と繰り返し処理の中の最後に入力処理を持ってくることになります。
したがって、入力処理を付け加えると、以下のような構造になります。
入力処理
until (繰り返しが終了する条件)
繰り返しで行う処理
入力処理
end
この「2-2-1」で示す型がuntil命令を使ったときのキーブレイク処理の基本型です。
下記に示したのは、スクリプトの構造を示したPAD図です。この図と実際のスクリプトを比較しながら、内容を理解してください。なお、入力データはキー順に並べ替えてあることが前提となっています。Rubyを利用して並べ替えを行う場合については、[2-4.ソート(並べ替え)処理]を参照してください。
【各キーの1件目を出力する場合のuntilを利用したキーブレイク処理のPAD図】
下記のPAD図は「ez-Chart ver1.0」 2003.2-3 cジュン All right reserved.を使用して作成されたものです。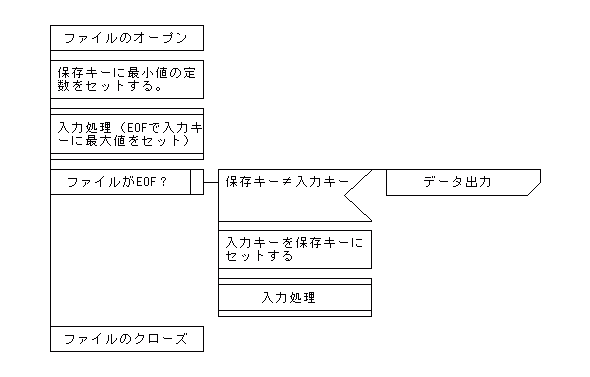
【untilを利用したときの入力処理のPAD図】
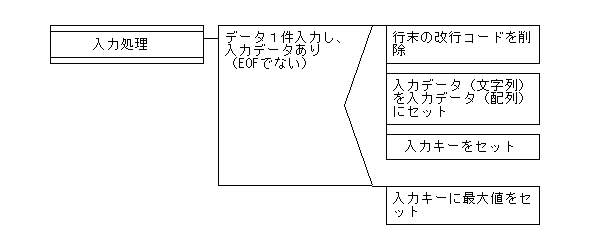
【スクリプト】
# keybreak1.rb
# 内容 : 同一キーの1件目のデータを出力する(until型)
# 前提 : キーごとに昇順に並べ替えておくこと
# Copyright (c) 2002-2015 Mitsuo Minagawa, All rights reserved.
# (minagawa@fb3.so-net.ne.jp)
# 使用方法 : c:\>ruby keybreak1.rb
#
# 入力ファイル
in1_file = open("input.txt","r")
# 出力ファイル
out1_file = open("output.txt","w")
# 初期値設定
in1_eof = ["ffffffff"].pack("h8") #ファイルの終了判定
in1_key = nil #入力キー
sv_key = nil #保存キー
in1_ctr = 0 #入力件数
# データ入力処理
class S_in1
def dataset(in1_file,in1_ctr,in1_eof)
if (line1 = in1_file.gets)
line1.chomp!
#タブ区切りのとき
# in1 = line1.split("\t",-1)
#カンマ区切りのとき
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
# キー項目が単独のとき
in1_key = in1[0]
# キー項目が複数のとき
# 1番目と2番目と3番目の項目がキーとなる場合
# in1_key = in1[0] + in1[1] + in1[2]
in1_ctr += 1
#入力ファイルが終了のとき
else
in1 = nil
#入力ファイルの終了判定(in1_eof)を入力キーにセット
in1_key = in1_eof
end
return in1,in1_ctr,in1_key
end
end
# データ入力処理(1件目)およびキー項目セット
s_in1 = S_in1.new
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
# 主処理
#入力ファイルが終了になるまで
until (in1_key == in1_eof)
if (sv_key != in1_key)
out1 = in1.join("\t")
out1_file.print(out1,"\n")
end
#入力したキーを保存
sv_key = in1_key
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
end
# ファイルのクローズ
in1_file.close
out1_file.close
【スクリプトとデータのサンプル】
【スクリプトの解説】
それでは、スクリプトの解説を個別に行っていきましょう。
初期値設定
# 初期値設定
in1_eof = ["ffffffff"].pack("h8") #ファイルの終了判定
in1_key = nil #入力キー
sv_key = nil #保存キー
in1_ctr = 0 #入力件数
各キーの1件目を出力する場合は、1件前のレコードのキーだけを保存しておき、その保存したキーと入力レコードのキーが異なっているかどうかによって、各キーごとの1件目のデータかどうかを判断します。ただし、入力レコードが1件目の場合は、保存キーには何もセットされていないので、あらかじめ1件目のレコードのキーとは異なる、何らかの値をセットしておく必要があります。ここでは、論理値として「偽」を示す値である「nil」を「sv_key」にセットしています。これにより、1件目のレコードについても必ず保存キーと異なることになり、各キーの1件目でもある、最初のレコードについても必ず出力されるようになるのです。
初期値設定では、まず、文字列の最大値である「in1_eof 」を設定しておきます。
このin1_eofをin1_keyに代入することで入力ファイルが終了したことを示します。
この項目は、EOFを検出した場合に処理を変える場合に使います。たとえば、入力データの全件について、ある特定の項目の合計値を計算して、出力する場合、出力するタイミングはEOFを検出した後になります。EOFを検出したときにキー項目に「in1_eof」という変数の値を代入することでEOFになったかどうかを判定します。
これは偽の値(nil)を使用してもかまいません。
一般的な入力処理では、他にないキー項目であれば、EOFを検出したかどうかを知るためには、どんな内容でもかまいません。ただし、キーブレイク処理やマッチング処理では、キー項目順に昇順でデータを並べ替えておくことが一般的ですので、入力データを読んで行くにつれて、キー項目は大きくなり、最後のデータでキー項目が該当ファイル内では最大値で終わることになります。
このとき、キー項目がファイルのEOFを検出するための項目を兼ねていると便利なため、EOFを検出したときに、通常では設定できない最大値を設定します。
各キーの1件目を出力する場合は、1件前のレコードのキーだけを保存しておき、その保存したキーと入力レコードのキーが異なっているかどうかによって、各キーごとの1件目のデータかどうかを判断します。
ただし、入力レコードが1件目の場合は、「1件前」のレコードは存在しません。したがって、保存キーには何もセットされていないことになります。こうしたことに対応するため、あらかじめ1件目のレコードのキーとは異なる、何らかの値を保存キーにセットしておく必要があります。ここでは、nilをセットしていますが、最小値を示す値を16進数で初期設定してもかまいません。
こうした初期設定を行うことにより、1件目のレコードについても必ず保存キーと異なることになり、各キーごとの1件目のレコードについて、必ず出力されるようになります。
それ以外に初期値として設定しておくような項目があれば、ここに設定しておきます。
入力処理
# データ入力処理
class S_in1
def dataset(in1_file,in1_ctr,in1_eof)
if (line1 = in1_file.gets)
line1.chomp!
#タブ区切りのとき
# in1 = line1.split("\t",-1)
#カンマ区切りのとき
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
# キー項目が単独のとき
in1_key = in1[0]
# キー項目が複数のとき
# 1番目と2番目と3番目の項目がキーとなる場合
# in1_key = in1[0] + in1[1] + in1[2]
in1_ctr += 1
#入力ファイルが終了のとき
else
in1 = nil
#入力ファイルの終了判定(in1_eof)を入力キーにセット
in1_key = in1_eof
end
return in1,in1_ctr,in1_key
end
end
Rubyは、オブジェクト指向言語なので、入力処理のようなサプルーチンを「ユーザ定義クラス」を使って定義します。ユーザ定義クラスは、
class クラス名
・・・・・
・・・・・
end
という形式で指定します。以下のサンプルでは、「class S_in1」から同じカラムで始まる「end」まで(「s_in1 = S_in1.new」の行の直前)がユーザ定義クラスになります。
サブルーチンとは、何らかの処理を行う部分をまとめて独立させたもので、通常は、そのスクリプトの中で2か所以上で同じような処理を行う場合、その共通する部分を抽出して、サブルーチンにします。こうすることで、将来、スクリプトを修正する場合に修正しやすくするだけでなく、修正すべき箇所以外を修正してしまう誤りを避けることができるようになります。なお、Rubyでは、ユーザ定義クラスは、実際にユーザ定義クラスを呼び出す場所よりも前に定義しておく必要があります。この点がPerlとは異なる点です。
クラス名は英大文字で始める決まりになっていますので、ここでは、「S_in1」という名称にしています。クラス名には、英大文字で始まっていれば、どのような名称でもいいのですが、ひらがなやカタカナ、漢字などは誤動作の可能性もあるので避けるべきです(したがって、半角の英数字のみを使用することをお勧めします)。
また、ユーザ定義クラスをもとにインスタンスを作成するには、
s_in1 = S_in1.new
のように「new」メソッドを利用して、変数(ここでは「s_in1」)にセットします。実際に値をセットするには、このインスタンス変数を利用して、ユーザ定義クラスの中で指定したメソッド定義(defで定義している部分)を使います。ここでは、
s_in1.dataset(in1_file,in1_ctr,high_value)
のようにすることで実際の処理が可能になります。
メソッド定義は、引数をセットすることができます。この例では、入力ファイルを示す変数(in1_file)と入力件数、入力データがEOFのときに入力キーにセットするための値(high_value)をセットしています。これにより、メソッド定義内部で
in1_file.gets
とすることで、入力レコードが1件ずつ入力でき、配列に展開することができます。戻り値は入力データの配列と入力件数、入力キーをセットした配列になります(具体的には「return in1,in1_ctr,in1_key」とします)。メソッド定義の外で利用したい項目については、必ず「戻り値」として指定しておきます。
主処理およびキーブレイク処理
# 主処理
#入力ファイルが終了になるまで
until (in1_key == in1_eof)
if (sv_key != in1_key)
out1 = in1.join("\t")
out1_file.print(out1,"\n")
end
#入力したキーを保存
sv_key = in1_key
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
end
until の条件は、入力データが終了(EOF)したときの条件を入れます。
EOFを判定する項目とキー項目を別々にとってもかまわないのですが、終了条件が複雑になるだけでほとんどメリットはありません。むしろ、同じ項目にしたほうがわかりやすいことが多いのです。
キーブレイク処理は、untilのループ内で先頭に置きます。untilのループに入る前に最初に1件目の入力をしているので、最初にループに入った直後にキーブレイク処理が発生することになります。
また、最後の入力データだけが異なるキー項目を持っていたとしても、EOFは入力処理を行った後に検出するため、必ずキーブレイク処理が発生します。
このスクリプトでは、入力データをすべて出力していますが、何らかの項目に限定するのか、計算を行うのかによって、必要な処理に変更します。
sv_key = in1_key
(in1,in1_ctr,in1_key) = s_in1.dataset(in1_file,in1_ctr,in1_eof)
キーブレイク処理の後、入力処理の前で入力データのキーを保存しておきます。保存しないと、現在入力しているデータの情報しか持っていないため、キーブレイクしたかどうか判断できなくなります。
その他のデータを保存したり、集計値を設定する必要があれば、ここに指定しておきます。
"s_in1.dataset"はデータ入力処理です。引数は入力ファイルと入力件数、EOFを示すin1_eofの3つです。これらの引数はすべて"dataset"メソッドの内部で使用します。データ入力処理は、untilのループ内の最後に置きます。入力処理でEOFが検出できれば、untilのループの外に出ることになり、EOFでなければ(つまり、入力データがあれば)、再度、untilのループの中の処理を最初から繰り返します。
その他注意すべきこと
その他、注意すべき点は入力データがタブ区切りなどの場合とキーが複数ある場合の処理です。
上記のスクリプトでは、入力ファイルがCSV形式であれば、すべて対応できるようになっていますが、引用符(")をつけないCSV形式(いわゆるCSV2形式と呼ばれるものです。CSV2形式については、[3-1-1.固定長データとCSVデータ]を参照してください)であれば、
in1 = (line1 + ',')
.scan(/"([^"\\]*(?:\\.[^"\\]*)*)",|([^,]*),/)
.collect{|x,y| y || x.gsub(/(.)/, '\1')}
上記の箇所を
in1 = line1.split(",",-1)
と変更します。
また、入力ファイルがタブ区切りの場合は以下のようにします。
入力データがタブ区切りの場合、
in1 = line1.split("\t",-1)
とします。
キーが複数の項目から成り立っている場合は、
「$in1_key = $in1[0]」の部分を
in1_key = in1[0] + in1[1] + in1[2]
のように変更します(文字列の連結は「+」(プラス)を使います)。
【入力データ(input.txt)】
aaa,1 aaa,2 aaa,3 bbb,1 ccc,1 ccc,2 ddd,1 ddd,2 ddd,3 ddd,4 eee,1 fff,1 ggg,1 hhh,1 hhh,2 hhh,3
【出力データ(output.txt)】
aaa,1 bbb,1 ccc,1 ddd,1 eee,1 fff,1 ggg,1 hhh,1
Copyright (c) 2004-2015 Mitsuo Minagawa, All rights reserved.