■Windows版Perlの細道・けもの道
■ナビゲータ
rubyではどう処理する?
同じことをrubyではこうしています。2.基本編
2-3.マッチング(照合)処理
2-3-4.1対nマッチング(照合)
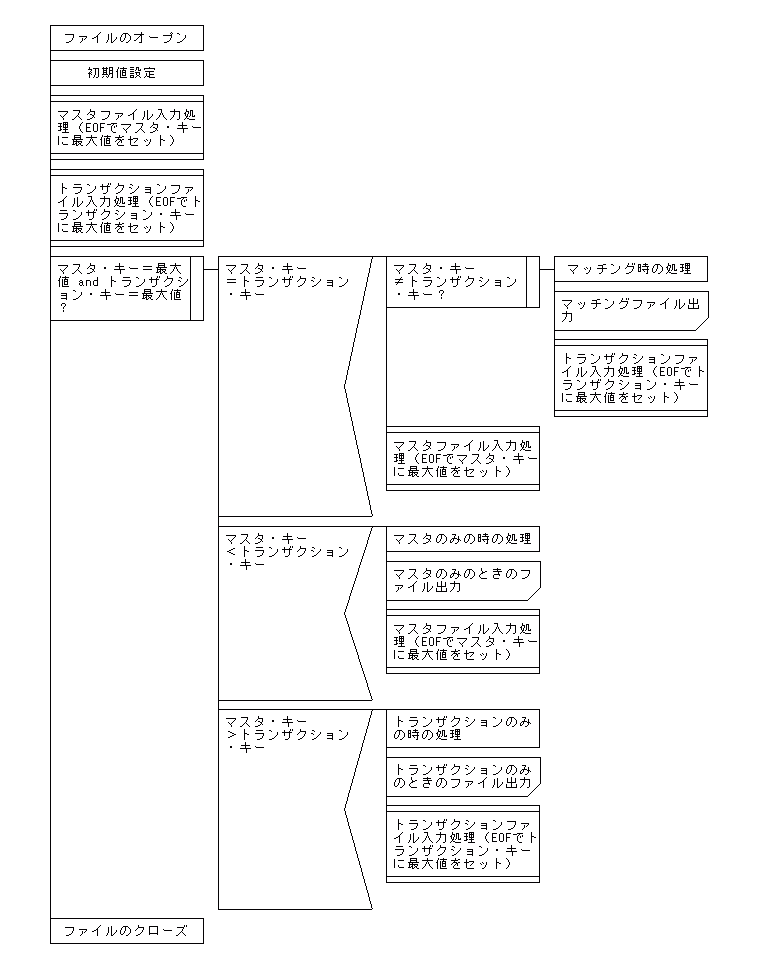
2つのCSVファイルを読み込んで、同一のキー項目を元に照合を行うスクリプトです。2つのファイルは「マスタファイル」と「トランザクションファイル」と呼びます。照合した結果により、3つのファイルに、<ふるいわけ>をします。3つのファイルとは、、該当するキー項目が「マスタファイル」と「トランザクションファイル」の両者に存在する<マッチングファイル>、該当するキー項目が「マスタファイル」にしか存在しない<マスタオンリーファイル>、該当するキー項目が「トランザクションファイル」にしか存在しない<トランザクションオンリーファイル>のことです。
「1対nマッチング(照合)」は、「トランザクションファイル」において、同一のキーを持つレコードが複数存在する場合のマッチング(照合)処理です。
1対1マッチング(照合)との相違は、マスタファイルのキーとトランザクションファイルのキーがマッチしたとき、トランザクションファイルについて繰り返し処理を行う点です。繰り返し処理は「until」を利用し、「until」処理の内部でトランザクションファイルを入力しています。「until」処理が終了する条件は、マスタファイルのキーと異なることです。
この例では、「マッチング(照合)したときの処理」を「until」処理の内部で行っていますが、トランザクションファイルの合計値を出力するような場合は、「until」処理を抜けた後に行うことになります。
下記に示したのは、スクリプトの構造を示したPAD図です。この図と実際のスクリプトを比較しながら、内容を理解してください。なお、入力データはキー順に並べ替えてあることが前提となっています。Perlを利用して並べ替えを行う場合については、[2-4.ソート(並べ替え)処理]を参照してください。
並べ替えをしなくても1対nマッチング(照合)を行うことができるスクリプトについては[2-3-7.ハッシュを使った1対nマッチング(照合)]にあります。
マッチング(照合)した場合は、「マスタファイル」と「トランザクションファイル」の両方が元データになりますが、どちらのファイルのデータをどのように編集するかは、それぞれのケースによって異なるので、各自工夫してください。
「マスタオンリーの処理」と「トランザクションオンリーの処理」では、それぞれ「マスタファイル」や「トランザクションファイル」からすべてのデータをセットして、出力していますが、必要に応じて、条件をつけたり、集計したり、必要な項目だけをセットするなど、内容を変更して利用してください。
【1対nマッチング(照合)処理のPAD図】
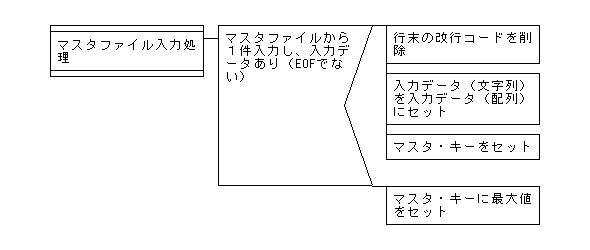
【1対nマッチング(照合)処理でのマスタファイル入力処理のPAD図】
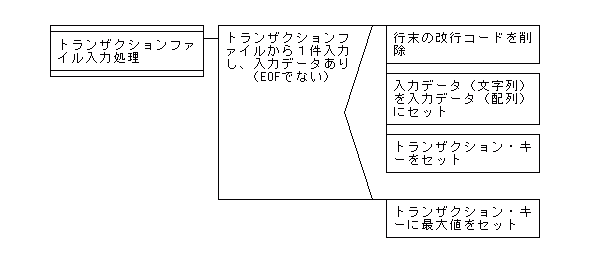
【1対nマッチング処理でのトランザクションファイル入力処理のPAD図】
【スクリプト】
# matching2.pl
# 内容 : マッチングプログラム(2ファイルの1対nマッチングプログラム)
# 前提 : マスタファイルとトランザクションファイルの両方を
# マッチングするキーごとに昇順に並べ替えておくこと
# Copyright (c) 2002-2011 Mitsuo Minagawa, All rights reserved.
# (minagawa@fb3.so-net.ne.jp)
# 使用方法 : c:\>perl matching2.pl
#
# ファイルのオープン
open(IN1,"master.txt"); #マスターファイル
open(IN2,"transaction.txt"); #トランザクションファイル
open(OUT1,">matching.txt"); #マッチングしたファイル
open(OUT2,">masteronly.txt"); #マスタのみのファイル
open(OUT3,">tranonly.txt"); #トランザクションのみのファイル
# 初期値設定
$high_value = pack("h8","ffffffff"); #終了判定
$low_value = pack("h8","00000000"); #low-value
$in1_key = $low_value; #マスタキー
$in2_key = $low_value; #トランザクションキー
# 1件目のデータ入力
s_in1();
s_in2();
# 主処理
until ($in1_key eq $high_value && $in2_key eq $high_value) {
# マッチング(照合)の時(両方のファイルにデータがある)
if ($in1_key eq $in2_key) {
until ($in1_key ne $in2_key) {
s_match();
s_in2();
}
s_in1();
}
# マスタオンリーの時(マスタファイルだけにデータがある)
elsif ($in1_key lt $in2_key) {
s_master_only();
s_in1();
}
# トランザクションオンリーの時(トランザクションファイルだけにデータがある)
elsif ($in1_key gt $in2_key) {
s_trans_only();
s_in2();
}
}
# マスタファイル入力
sub s_in1 {
if ($line1 = <IN1>) {
chomp($line1);
#---区切り文字により、処理を変更する----------
#タブ区切りのとき
# @in1 = split("\t",$line1);
#カンマ区切りのとき
my $tmp = $line1;
$tmp =~ s/(?:\x0D\x0A|[\x0D\x0A])?$/,/;
@in1 = map {/^"(.*)"$/ ? scalar($_ = $1, s/""/"/g, $_) : $_}
($tmp =~ /("[^"]*(?:""[^"]*)*"|[^,]*),/g);
#-----------------
$in1_key = $in1[0];
}
else { #マスターファイルが終了のとき
$in1_key = $high_value;
}
}
# トランザクションファイル入力
sub s_in2 {
if ($line2 = <IN2>) {
chomp($line2);
#---区切り文字により、処理を変更する----------
#タブ区切りのとき
# @in2 = split("\t",$line2);
#カンマ区切りのとき
my $tmp = $line2;
$tmp =~ s/(?:\x0D\x0A|[\x0D\x0A])?$/,/;
@in2 = map {/^"(.*)"$/ ? scalar($_ = $1, s/""/"/g, $_) : $_}
($tmp =~ /("[^"]*(?:""[^"]*)*"|[^,]*),/g);
#-----------------
$in2_key = $in2[0];
}
else { #トランザクションファイルが終了のとき
$in2_key = $high_value;
}
}
# マッチング(照合)時の処理
sub s_match {
$out1 = join("\t",@in2);
print OUT1 "$out1\n";
}
# マスタオンリー時の処理
sub s_master_only {
$out2 = join("\t",@in1);
print OUT2 "$out2\n";
}
# トランザクションオンリー時の処理
sub s_trans_only {
$out3 = join("\t",@in2);
print OUT3 "$out3\n";
}
# ファイルのクローズ
close(IN1);
close(IN2);
close(OUT1);
close(OUT2);
close(OUT3);
【スクリプトとデータのサンプル】
【スクリプトの解説】
それでは、スクリプトの解説を個別に行っていきましょう。
1対nマッチング(照合)
# マッチング(照合)の時(両方のファイルにデータがある)
if ($in1_key eq $in2_key) {
until ($in1_key ne $in2_key) {
s_match();
s_in2();
}
s_in1();
}
「1対nマッチング(照合)」が「1対1マッチング(照合)」と異なっているのは、マッチしたときの処理だけです。通常、マッチしたときの処理は1回しか行いませんが、「1対nマッチング(照合)」ではuntil処理によって、トランザクションファイルのキーが変わるまで処理を続けています。
この例では、1件ずつ出力しているだけですが、例えば合計値を算出する場合には「s_match」サブルーチンとマッチング(照合)の時の処理を以下のように変更します。サブルーチンには特に引数は必要ありません。このあたりはRubyと異なる点になります。
マッチング(照合)したときの処理
# マッチング(照合)時の処理
sub s_match {
$total += $in2[1];
}
# マッチング(照合)の時(両方のファイルにデータがある)
if ($in1_key eq $in2_key) {
until ($in1_key ne $in2_key) {
s_match();
s_in2();
}
$out1 = join("\t",$in1_key,$total);
print OUT1 "$out1\n";
$total = 0;
s_in1();
}
その他注意すべきこと
その他、注意すべき点は入力データがタブ区切りなどの場合とキーが複数ある場合の処理です。
上記のスクリプトでは、入力ファイルがCSVファイルであれば、どのようなものでも対応できるようになっています。具体的には以下の箇所になります。
CSV形式の入力データを配列に変換する
my $tmp = $line1;
$tmp =~ s/(?:\x0D\x0A|[\x0D\x0A])?$/,/;
@in1 = map {/^"(.*)"$/ ? scalar($_ = $1, s/""/"/g, $_) : $_}
($tmp =~ /("[^"]*(?:""[^"]*)*"|[^,]*),/g);
上記のスクリプトはCSV2形式以外の引用符(")を使用する場合を含め、あらゆるCSVファイルに対応できるようになっています(CSV2形式などについては、[3-1-1.固定長データとCSVデータ]を参照してください)が、このCSVファイルに分解するロジックは、大崎 博基(OHZAKI Hiroki)さんの「Perlメモ」に記載されていたものを参考にしています。また、CSV2形式のCSVファイルであれば、上記のスクリプトは以下のように簡略化できます。
1.入力データがCSV2形式の場合、
@in1 = split(",",$line1,-1);
とします。
2.入力データがタブ区切りの場合、
@in1 = split("\t",$line1,-1);
とします。
3.キーが複数の項目から成り立っている場合は、
「$in1_key = $in1[0]」の部分を
$in1_key = $in1[0].$in1[1].$in1[2];
のように変更します(文字列の連結は「.」(ピリオド)を使います)。
【入力データ:マスタファイル(master.txt)】
01,11111 02,22222 03,33333 05,44444 07,77777 08,88888 09,99999
【入力データ:トランザクションファイル(transaction.txt)】
01,100 01,101 01,102 02,200 04,400 04,401 04,402 04,403 06,600 06,601 07,700 08,800 09,900 10,1000 10,1010 10,1020
【出力データ:マッチング(照合)ファイル(matching.txt)】
01 100 01 101 01 102 02 200 07 77777 08 88888 09 99999
【出力データ:マスタオンリーファイル(masteronly.txt)】
03 33333 05 44444
【出力データ:トランザクションオンリーファイル(tranonly.txt)】
04 400 04 401 04 402 04 403 06 600 06 601 10 1000 10 1010 10 1020
Copyright (c) 2004-2013 Mitsuo Minagawa, All rights reserved.