■Windows版Perlの細道・けもの道
■ナビゲータ
rubyではどう処理する?
同じことをrubyではこうしています。2.基本編
2-3.マッチング(照合)処理
2-3-2.1対1マッチング(照合)
2つのCSVファイルを読み込んで、同一のキー項目を元に照合を行うスクリプトです。2つのファイルは「マスタファイル」と「トランザクションファイル」と呼びます。照合した結果により、3つのファイルに、<ふるいわけ>をします。3つのファイルとは、、該当するキー項目が「マスタファイル」と「トランザクションファイル」の両者に存在する<マッチングファイル>、該当するキー項目が「マスタファイル」にしか存在しない<マスタオンリーファイル>、該当するキー項目が「トランザクションファイル」にしか存在しない<トランザクションオンリーファイル>のことです。
以下のスクリプトは、「マスタファイル」も「トランザクションファイル」もそれぞれ、同一のキーを持つレコードが1つしか存在しない場合のマッチング(照合)処理です。2つのファイルを照合し、それぞれの相違点や一致点が容易に把握できるという点で、「キーブレイク処理」と並んで応用範囲の広いプログラムです。
下記に示したのは、スクリプトの構造を示したPAD図です。この図と実際のスクリプトを比較しながら、内容を理解してください。なお、入力データはキー順に並べ替えてあることが前提となっています。Perlを利用して並べ替えを行う場合については、[2-4.ソート(並べ替え)処理]を参照してください。
並べ替えをしなくても1対1マッチング(照合)を行うことができるスクリプトについては[2-3-5.ハッシュを使った1対1マッチング(照合)]にあります。
マッチング(照合)した場合は、「マスタファイル」と「トランザクションファイル」の両方が元データになりますが、どちらのファイルのデータをどのように編集するかは、それぞれのケースによって異なるので、各自工夫してください。
「マスタオンリーの処理」と「トランザクションオンリーの処理」では、それぞれ「マスタファイル」や「トランザクションファイル」からすべてのデータをセットして、出力していますが、必要に応じて、条件をつけたり、集計したり、必要な項目だけをセットするなど、内容を変更して利用することになります。
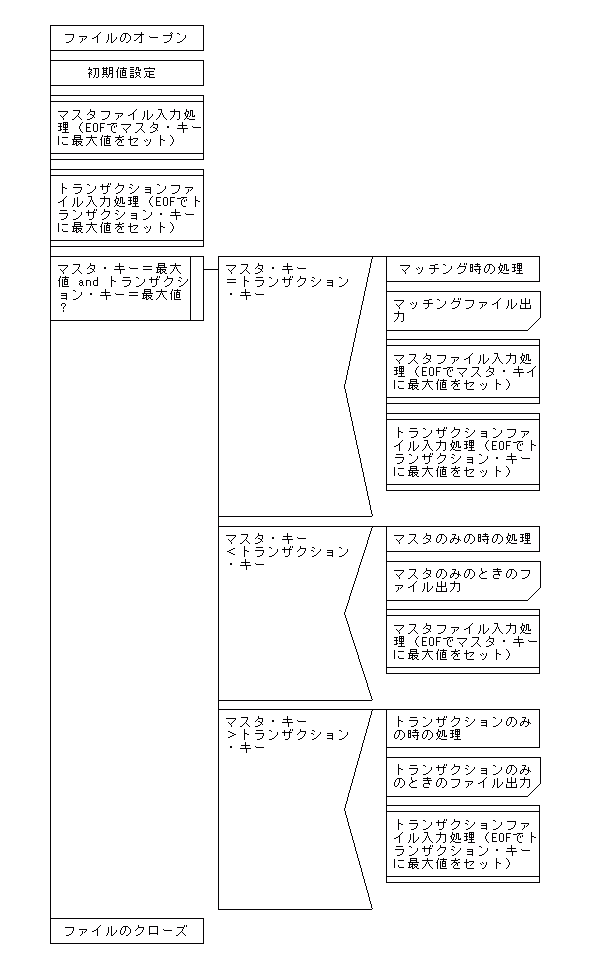
【1対1マッチング(照合)処理のPAD図】
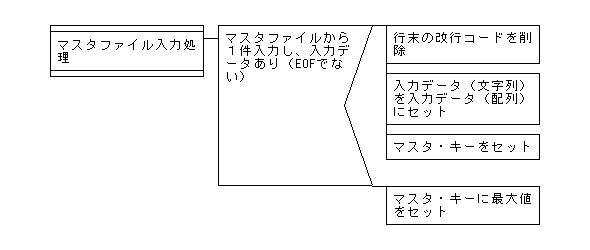
【1対1マッチング(照合)処理でのマスタファイル入力処理のPAD図】
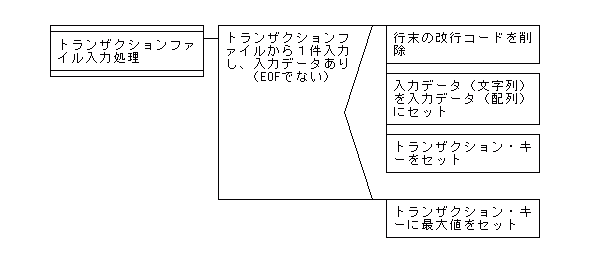
【1対1マッチング(照合)処理でのトランザクションファイル入力処理のPAD図】
【スクリプト】
# matching1.pl
# 内容 : マッチングプログラム(2ファイルの1対1マッチングプログラム)
# 前提 : マスタファイルとトランザクションファイルの両方を
# マッチングするキーごとに昇順に並べ替えておくこと
# Copyright (c) 2002-2011 Mitsuo Minagawa, All rights reserved.
# (minagawa@fb3.so-net.ne.jp)
# 使用方法 : c:\>perl matching1.pl
#
# ファイルのオープン
open(IN1,"master.txt"); #マスタファイル
open(IN2,"transaction.txt"); #トランザクションファイル
open(OUT1,">matching.txt"); #マッチングしたファイル
open(OUT2,">masteronly.txt"); #マスタのみのファイル
open(OUT3,">tranonly.txt"); #トランザクションのみのファイル
# 初期値設定
$high_value = pack("h8","ffffffff"); #終了判定
$low_value = pack("h8","00000000"); #low-value
$in1_key = $low_value; #マスタキー
$in2_key = $low_value; #トランザクションキー
# 1件目のデータ入力
s_in1();
s_in2();
# 主処理
until ($in1_key eq $high_value && $in2_key eq $high_value) {
# マッチング(照合)の時(両方のファイルにデータがある)
if ($in1_key eq $in2_key) {
s_match();
s_in1();
s_in2();
}
# マスタオンリーの時(マスタファイルだけにデータがある)
elsif ($in1_key lt $in2_key) {
s_master_only();
s_in1();
}
# トランザクションオンリーの時(トランザクションファイルだけにデータがある)
elsif ($in1_key gt $in2_key) {
s_trans_only();
s_in2();
}
}
# マスタファイル入力
sub s_in1 {
if ($line1 = <IN1>) {
chomp($line1);
#---区切り文字により、処理を変更する----------
#タブ区切りのとき
# @in1 = split("\t",$line1);
#カンマ区切りのとき
my $tmp = $line1;
$tmp =~ s/(?:\x0D\x0A|[\x0D\x0A])?$/,/;
@in1 = map {/^"(.*)"$/ ? scalar($_ = $1, s/""/"/g, $_) : $_}
($tmp =~ /("[^"]*(?:""[^"]*)*"|[^,]*),/g);
#-----------------
$in1_key = $in1[0];
}
else { #マスタファイルが終了のとき
$in1_key = $high_value;
}
}
# トランザクションファイル入力
sub s_in2 {
if ($line2 = <IN2>) {
chomp($line2);
#---区切り文字により、処理を変更する----------
#タブ区切りのとき
# @in2 = split("\t",$line2);
#カンマ区切りのとき
my $tmp = $line2;
$tmp =~ s/(?:\x0D\x0A|[\x0D\x0A])?$/,/;
@in2 = map {/^"(.*)"$/ ? scalar($_ = $1, s/""/"/g, $_) : $_}
($tmp =~ /("[^"]*(?:""[^"]*)*"|[^,]*),/g);
#-----------------
$in2_key = $in2[0];
}
else { #トランザクションファイルが終了のとき
$in2_key = $high_value;
}
}
# マッチング(照合)時の処理
sub s_match {
$out1 = join("\t",@in1);
print OUT1 "$out1\n";
}
# マスタオンリー時の処理
sub s_master_only {
$out2 = join("\t",@in1);
print OUT2 "$out2\n";
}
# トランザクションオンリー時の処理
sub s_trans_only {
$out3 = join("\t",@in2);
print OUT3 "$out3\n";
}
# ファイルのクローズ
close(IN1);
close(IN2);
close(OUT1);
close(OUT2);
close(OUT3);
【スクリプトとデータのサンプル】
【スクリプトの解説】
それでは、スクリプトの解説を個別に行っていきましょう。
初期値設定
# 初期値設定
$high_value = pack("h8","ffffffff"); #終了判定
$low_value = pack("h8","00000000"); #low-value
$in1_key = $low_value; #マスタキー
$in2_key = $low_value; #トランザクションキー
初期値設定では、文字列の最大値である「$high_value」と文字列の最小値である「$low_value」、マスタファイルの入力キー「$in1_key」、トランザクションファイルの入力キー「$in2_key」を設定しておきます。ただし、マスタファイルの入力キー「$in1_key」とトランザクションファイルの入力キー「$in2_key」は、主処理のuntil文の中の判定に使うため、ここでは文字列の最小値である「$low_value」を初期値していますが、後で必ず値が入るので、初期値を設定しておかなくても特に問題はありません。
「$high_value」はCOBOLで使用される定数の名称ですが、入力ファイルが終了したことを示すEOFを検出したときに設定することに利用します。
それ以外に初期値として設定しておくような項目があれば、ここに設定しておきます。
入力処理
# 1件目のデータ入力 s_in1(); s_in2();
untilループ処理を行う場合は、必ず、ループ処理の前に1件目のデータを入力するための処理を行います。
入力処理は、untilループの中で最後でも行うため、サブルーチンとして別に設定しています。
主処理
# 主処理
until ($in1_key eq $high_value && $in2_key eq $high_value) {
# マッチング(照合)の時(両方のファイルにデータがある)
if ($in1_key eq $in2_key) {
s_match();
s_in1();
s_in2();
}
# マスタオンリーの時(マスタファイルだけにデータがある)
elsif ($in1_key lt $in2_key) {
s_master_only();
s_in1();
}
# トランザクションオンリーの時(トランザクションファイルだけにデータがある)
elsif ($in1_key gt $in2_key) {
s_trans_only();
s_in2();
}
}
untilの条件は、入力データが終了(EOF)したときの条件を入れます。ここでは、マスタファイルとトランザクションファイルの両方のデータがなくなるまで処理を続けていますが、処理内容によってはマスタファイルが終了するだけ、またはトランザクションファイルが終了するだけで処理全体を終了させることがありますので、必要に応じて変更します。
whileのループにしたい場合は、以下のようにwhileの中の条件を「入力データが終了(EOF)しないときの条件」にします。
while ($in1_key ne $high_value || $in2_key ne $high_value)
キーブレイク処理のように「ファイルハンドルから入力データを1件、読み込む処理」にすると、マスタファイルとトランザクションファイルの両方を常に読み込む処理になってしまうため、マッチング(照合)処理を正しく行うことができなくなります。
untilのループ内では、「マッチング(照合)の時」、「マスタオンリーの時」、「トランザクションオンリーの時」のそれぞれに場合分けして処理を行います。ここでも、例えば、マッチング(照合)したときだけのデータが必要であれば、それ以外の処理はデータ入力だけを行うように変更します。
マッチング(照合)処理
# マッチング(照合)時の処理
sub s_match {
$out1 = join("\t",@in1);
print OUT1 "$out1\n";
}
# マスタオンリー時の処理
sub s_master_only {
$out2 = join("\t",@in1);
print OUT2 "$out2\n";
}
# トランザクションオンリー時の処理
sub s_trans_only {
$out3 = join("\t",@in2);
print OUT3 "$out3\n";
}
「マッチング(照合)の時」、「マスタオンリーの時」、「トランザクションオンリーの時」のそれぞれに場合分けしたときの具体的な処理をここで設定しておきます。それぞれの処理の場合、マスタファイルとトランザクションファイルのどちらからどのような項目を持ってくるのかについては、実際の処理にあわせて変更します。
上記の例では、「マッチング(照合)時の処理」でマスタファイルからデータを持ってきていますが、処理の内容によっては、トランザクションファイルからデータを持ってくることもあります。また、上記の例ではすべての項目を出力していますが、必要な項目だけを出力したり、計算結果や内容を変換して出力したりします。
その他注意すべきこと
その他、注意すべき点は入力データがタブ区切りなどの場合とキーが複数ある場合の処理です。
上記のスクリプトでは、入力ファイルがCSVファイルであれば、どのようなものでも対応できるようになっています。具体的には以下の箇所になります。
CSV形式の入力データを配列に変換する
my $tmp = $line1;
$tmp =~ s/(?:\x0D\x0A|[\x0D\x0A])?$/,/;
@in1 = map {/^"(.*)"$/ ? scalar($_ = $1, s/""/"/g, $_) : $_}
($tmp =~ /("[^"]*(?:""[^"]*)*"|[^,]*),/g);
上記のスクリプトはCSV2形式以外の引用符(")を使用する場合を含め、あらゆるCSVファイルに対応できるようになっています(CSV2形式などについては、[3-1-1.固定長データとCSVデータ]を参照してください)が、このCSVファイルに分解するロジックは、大崎 博基(OHZAKI Hiroki)さんの「Perlメモ」に記載されていたものを参考にしています。また、CSV2形式のCSVファイルであれば、上記のスクリプトは以下のように簡略化できます。
1.入力データがCSV2形式の場合、
@in1 = split(",",$line1,-1);
とします。
2.入力データがタブ区切りの場合、
@in1 = split("\t",$line1,-1);
とします。
3.キーが複数の項目から成り立っている場合は、
「$in1_key = $in1[0]」の部分を
$in1_key = $in1[0].$in1[1].$in1[2];
のように変更します(文字列の連結は「.」(ピリオド)を使います)。
【入力データ:マスタファイル(master.txt)】
01,11111 02,22222 03,33333 05,44444 07,77777 08,88888 09,99999
【入力データ:トランザクションファイル(transaction.txt)】
01,100 02,200 04,400 06,600 07,700 08,800 09,900 10,1000
【出力データ:マッチング(照合)ファイル(matching.txt)】
01 11111 02 22222 07 77777 08 88888 09 99999
【出力データ:マスタオンリーファイル(masteronly.txt)】
03 33333 05 44444
【出力データ:トランザクションオンリーファイル(tranonly.txt)】
04 400 06 600 10 1000
Copyright (c) 2004-2013 Mitsuo Minagawa, All rights reserved.